Create an acoustic model
Acoustic model
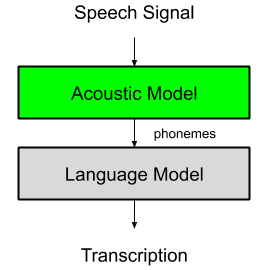
An acoustic model is a trained Neural Network that transform an audio signal input to a sequence or phonemes (or n-phones). An acoustic model is trained on a audio -> phonemes inputs.
Those phonemes are then mapped to words and utterances by the language model.
Acoustic models cover an entire language and therefore is created once for a given tongue.
Prerequisites
- You have a deployed stack with LinTO Platform Service Manager running.
- You have access to the LinTO Platform Service Manager Swagger at
[LINTO_STACK_DOMAIN]/stt-manager/api-doc/. - You have a trained acoustic model for your desired language. (We provides downloadable ready-made models at Download Section).
Creating an acoustic model.
On the swagger interface go to the Acoustic Model Section and select the Create Acoustic Model request and click on Try it out.
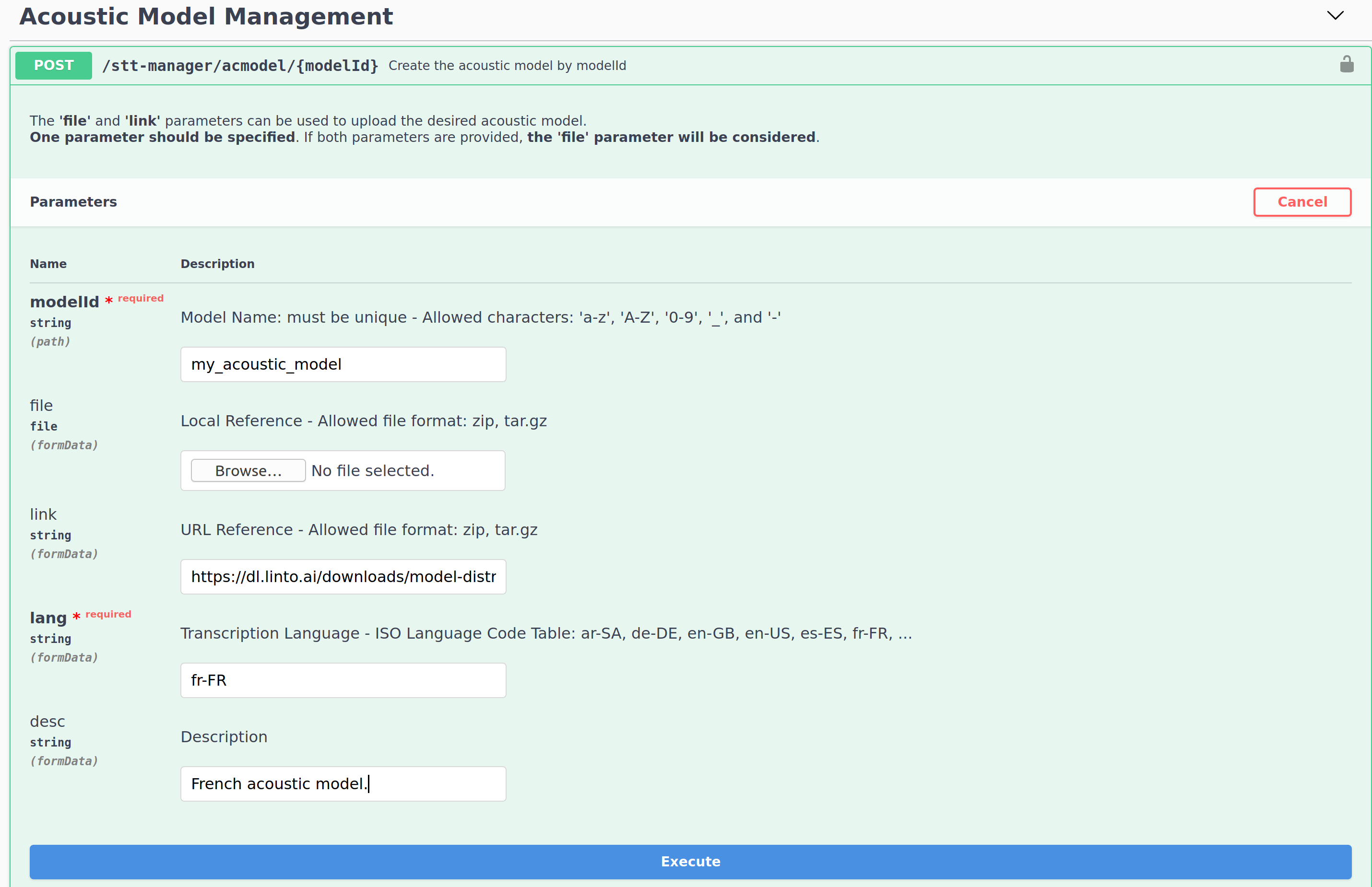
Request parameters:
- modelId : The name of your model.
- file: Model absolute path if the model already exist in your SHARED_FOLDER.
- link: URL of the model.
- lang: The model lang with ISO format.
- description: The model description.
Note that you must choose between file and link.
Once the paremeters are set. Click on execute and wait for the response.
If the request returns a 200, you successfuly created your acoustic model.
Check your model
On the swagger interface go to the Acoustic Model Section and select the get the acoustic model request and click on Try it out.
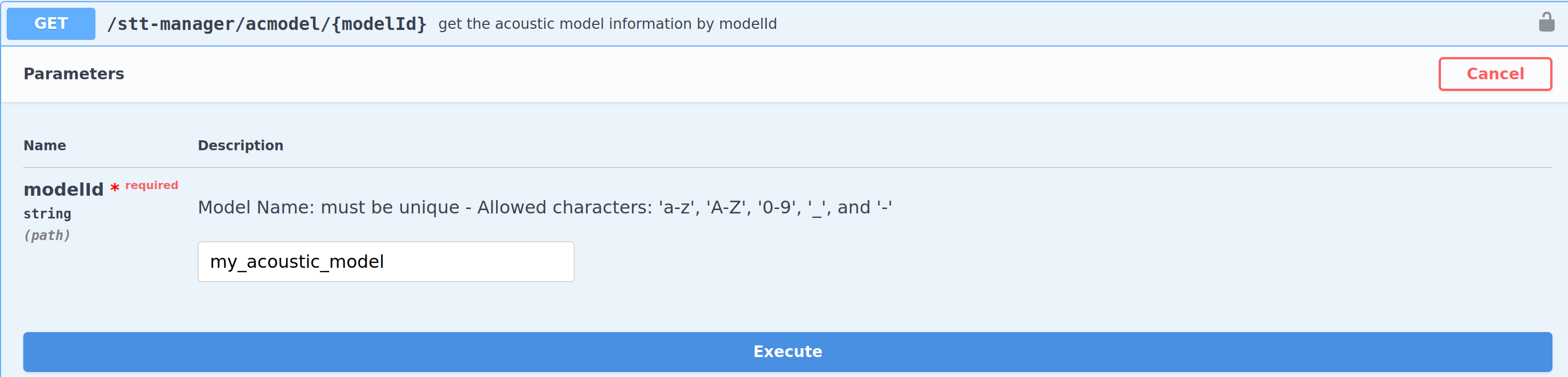
Set your newly created acoustic model ID and Execute. Your model should be displayed.