Automatic Speech Recognition
LINTO-PLATFORM-STT
LinTO-platform-stt can either be used as a standalone transcription service or deployed within a micro-services infrastructure using a message broker connector.
Pre-requisites
Hardware
To run the transcription models you'll need:
- At least 7Go of disk space to build the docker image.
- Up to 7GB of RAM depending on the model used.
- One CPU per worker. Inference time scales on CPU performances.
Model
LinTO-Platform-STT accepts two kinds of models:
- LinTO Acoustic and Languages models.
- Vosk models.
Docker
The transcription service requires docker up and running.
(micro-service) Service broker and shared folder
The STT only entry point in task mode are tasks posted on a message broker. Supported message broker are RabbitMQ, Redis, Amazon SQS. On addition, as to prevent large audio from transiting through the message broker, STT-Worker use a shared storage folder (SHARED_FOLDER).
Deploy linto-platform-stt
1- First step is to build or pull the image:
git clone https://github.com/linto-ai/linto-platform-stt.git
cd linto-platform-stt
docker build . -t linto-platform-stt:latest
or
docker pull lintoai/linto-platform-stt
2- Download the models
Have the acoustic and language model ready at AM_PATH and LM_PATH if you are using LinTO models. If you are using a Vosk model, have it ready at MODEL.
3- Fill the .env
cp .envdefault .env
| PARAMETER | DESCRIPTION | EXEMPLE |
|---|---|---|
| SERVING_MODE | STT serving mode see Serving mode | http|task|websocket |
| MODEL_TYPE | Type of STT model used | lin|vosk |
| ENABLE_STREAMING | Using http serving mode, enable the /streaming websocket route | true|false |
| SERVICE_NAME | Using the task mode, set the queue's name for task processing | my-stt |
| SERVICE_BROKER | Using the task mode, URL of the message broker | redis://my-broker:6379 |
| BROKER_PASS | Using the task mode, broker password | my-password |
| STREAMING_PORT | Using the websocket mode, the listening port for ingoing WS connexions. | 80 |
| CONCURRENCY | Maximum number of parallel requests | >1 |
Serving mode
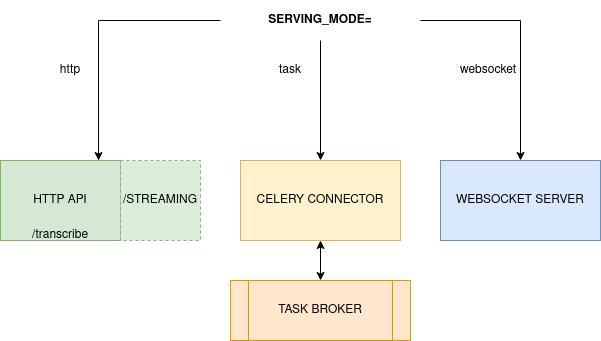
STT can be used three different ways:
- Through an HTTP API using the http's mode.
- Through a message broker using the task's mode.
- Through a websocket server websocket's mode.
Mode is specified using the .env value or environment variable SERVING_MODE.
SERVING_MODE=http
HTTP Server
The HTTP serving mode deploys an HTTP server and a swagger-ui to allow transcription request on a dedicated route.
The SERVING_MODE value in the .env should be set to http.
docker run --rm \
-p HOST_SERVING_PORT:80 \
-v AM_PATH:/opt/AM \
-v LM_PATH:/opt/LM \
--env-file .env \
linto-platform-stt:latest
This will run a container providing an HTTP API binded on the host port HOST_SERVING_PORT.
Parameters:
| PARAMETER | DESCRIPTION | EXEMPLE |
|---|---|---|
| HOST_SERVING_PORT | Host serving port | 80 |
| AM_PATH | Path to the acoustic model on the host machine mounted to /opt/AM | /my/path/to/models/AM_fr-FR_v2.2.0 |
| LM_PATH | Path to the language model on the host machine mounted to /opt/LM | /my/path/to/models/fr-FR_big-v2.2.0 |
| MODEL_PATH | Path to the model (using MODEL_TYPE=vosk) mounted to /opt/model | /my/path/to/models/vosk-model |
Micro-service & task broker
The HTTP serving mode connect a celery worker to a message broker.
The SERVING_MODE value in the .env should be set to task.
LinTO-platform-stt in task mode is not intended to be launch manually. However, if you intent to connect it to your custom message's broker here are the parameters:
You need a message broker up and running at MY_SERVICE_BROKER.
docker run --rm \
-v AM_PATH:/opt/models/AM \
-v LM_PATH:/opt/models/LM \
-v SHARED_AUDIO_FOLDER:/opt/audio \
--env-file .env \
linto-platform-stt:latest
Parameters:
| PARAMETER | DESCRIPTION | EXEMPLE |
|---|---|---|
| AM_PATH | Path to the acoustic model on the host machine mounted to /opt/AM | /my/path/to/models/AM_fr-FR_v2.2.0 |
| LM_PATH | Path to the language model on the host machine mounted to /opt/LM | /my/path/to/models/fr-FR_big-v2.2.0 |
| MODEL_PATH | Path to the model (using MODEL_TYPE=vosk) mounted to /opt/model | /my/path/to/models/vosk-model |
| SHARED_AUDIO_FOLDER | Shared audio folder mounted to /opt/audio | /my/path/to/models/vosk-model |
Websocket Server
Websocket server's mode deploy a streaming transcription service only.
The SERVING_MODE value in the .env should be set to websocket.
Usage is the same as the http streaming API
Usages
HTTP API
/healthcheck
Returns the state of the API
Method: GET
Returns "1" if healthcheck passes.
/transcribe
Transcription API
- Method: POST
- Response content: text/plain or application/json
- File: Wave file 16b 16Khz
Return the transcripted text using "text/plain" or a json object when using "application/json" structure as followed:
{
"text" : "This is the transcription",
"words" : [
{"word":"This", "start": 0.123, "end": 0.453, "conf": 0.9},
...
]
"confidence-score": 0.879
}
/streaming
The /streaming route is accessible if the ENABLE_STREAMING environment variable is set to true.
The route accepts websocket connexions. Exchanges are structured as followed:
- Client send a json
{"config": {"sample_rate":16000}}. - Client send audio chunk (go to 3- ) or {"eof" : 1} (go to 5-).
- Server send either a partial result
{"partial" : "this is a "}or a final result{"text": "this is a transcription"}. - Back to 2-
- Server send a final result and close the connexion.
Connexion will be closed and the worker will be freed if no chunk are received for 10s.
/docs
The /docs route offers a OpenAPI/swagger interface.
Through the message broker
STT-Worker accepts requests with the following arguments:
file_path: str, with_metadata: bool
- file_path: Is the location of the file within the shared_folder. /.../SHARED_FOLDER/{file_path}
- with_metadata: If True, words timestamps and confidence will be computed and returned. If false, the fields will be empty.
Return format
On a successfull transcription the returned object is a json object structured as follow:
{
"text" : "this is the transcription as text",
"words": [
{
"word" : "this",
"start": 0.0,
"end": 0.124,
"conf": 1.0
},
...
],
"confidence-score": ""
}
- The text field contains the raw transcription.
- The word field contains each word with their timestamp and individual confidence. (Empty if with_metadata=False)
- The confidence field contains the overall confidence for the transcription. (0.0 if with_metadata=False)
Test
Curl
You can test your http API using curl:
curl -X POST "http://YOUR_SERVICE:YOUR_PORT/transcribe" -H "accept: application/json" -H "Content-Type: multipart/form-data" -F "file=@YOUR_FILE;type=audio/x-wav"
License
This project is developped under the AGPLv3 License (see LICENSE).