Deploy a command transcription service
Command transcription service
A command transcription service allows to submit audio files to an API that will return a text transcription. File transcription can be used as itself and is a prerequisite of other uses. "Command" implies that the transcription is limited to sentences inputed beforehand.
Prerequisistes
- You have a deployed stack with LinTO Platform Service Manager running.
- You have access to the LinSTT-Service-Manager Swagger at
[LINTO_STACK_DOMAIN]/stt-manager/api-doc/. - You have created an acoustic model for your language. If not see Create an acoustic model
Creating the service
In the following steps we will create a command file transcription service.
- Create a command language model
- Create a file transcription service
- Populate your language model with command utterances
1- Create a command language model
In this step you will create a command language model.
A language model takes the phonemes extracted from the audio signal by the acoustic model and map them with known sentences.
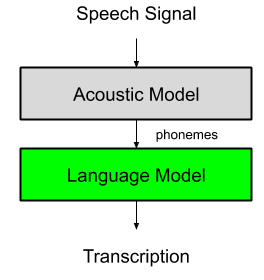
There are two approach to create a command language model:
- You can start with an empty language model. In that case, only the defined utterances will be recognized, words and sentence structures not defined won't be recognized.
- You can start with a small language model and add your specific commands. With that approach, the model will recognize the defined commands but will be able to accomodate a certain level of variations based on common language.
Connect to the STT Service Manager Swagger.
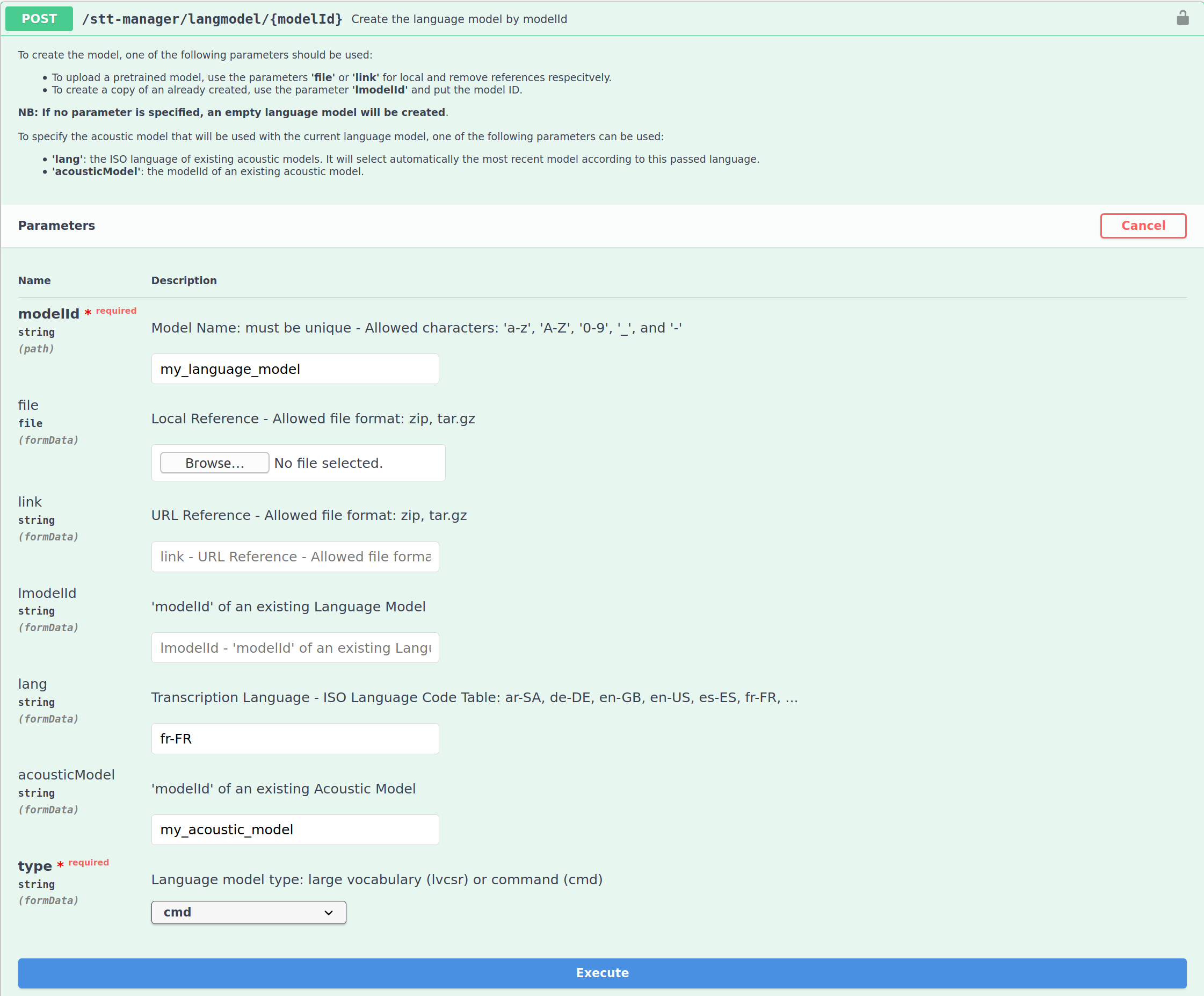
lang: The intended language.fileorlink: Set the path or the link of a small language model or leave it empty if you wish to create a strict command model.acousticModel: The acoustic model you created for the intended language.type: Select cmd for command.
Tap Execute and the STT-Manager should return a code 200.
Now you have a command language model set in your STT Service Manager.
2- Create a file transcription service
In this step we will create a command file transcription service.
The transcription service wrap the acoustic model and the language model to produce a transcription pipeline and provide a runtime API to submit transcription requests.
Connect to the STT Service Manager Swagger.
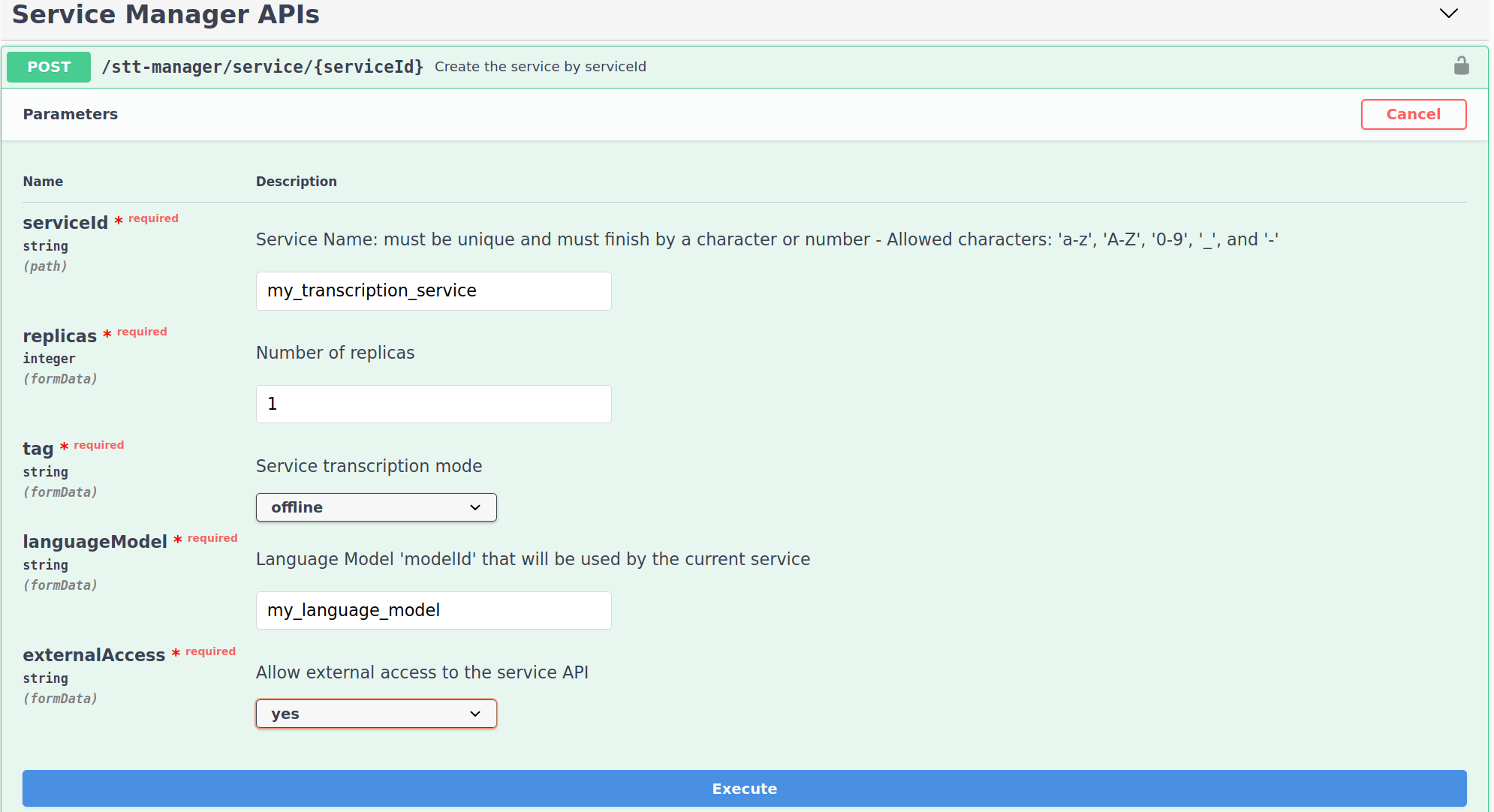
serviceId: Service Name.replica: Set the number of instance you wish to create (It can be changed later).tag: Set to offline for a file transcription service.languageModel: Set the modelId of the command language model created on the previous step.externalAccess: Whether or not the API can be accessed from outside the stack.
You have now a live command file transcription service deployed on your stack.
3- Populate the language model
To set-up the commands within the created language model you have two options:
- If the transcription service is used by an application created in the admin interface, the model will be automaticaly updated with the command utterances defined within the associated skills. You have nothing to do.
- If the transcription service meant to be used alone, you'll need to update it with the command sentences and entities.
Command utterances are comprised of 2 elements:
Intents: An intent is the applicative objective of the command. It is represented by a list of sentences designed to characterize an intention. For exemple, a weather application can be described with sentences such as "What's the weather like today", "How is the weather ?", "Is it raining ?", ... Feeding those sentences to the language model allow it to recognize them. Intents are primary designed for the NLU service but in this case they are a mean to specify sentences to the STT language graph.
Entities: Entities are sets of specifics arguments to be used inside intents. It can be locations, names, colors, ... It prevents the need to specify each combinaison of intent-entity. For exemple instead of declaring each weather-location : "What's the weather like in Paris", "What's the weather like in London", ... Entities allow to describe "What's the weather like in #location", the service manager mapping automaticaly each combinaison for the language model to recognize.
To specifify sentences and entities go to the swagger.
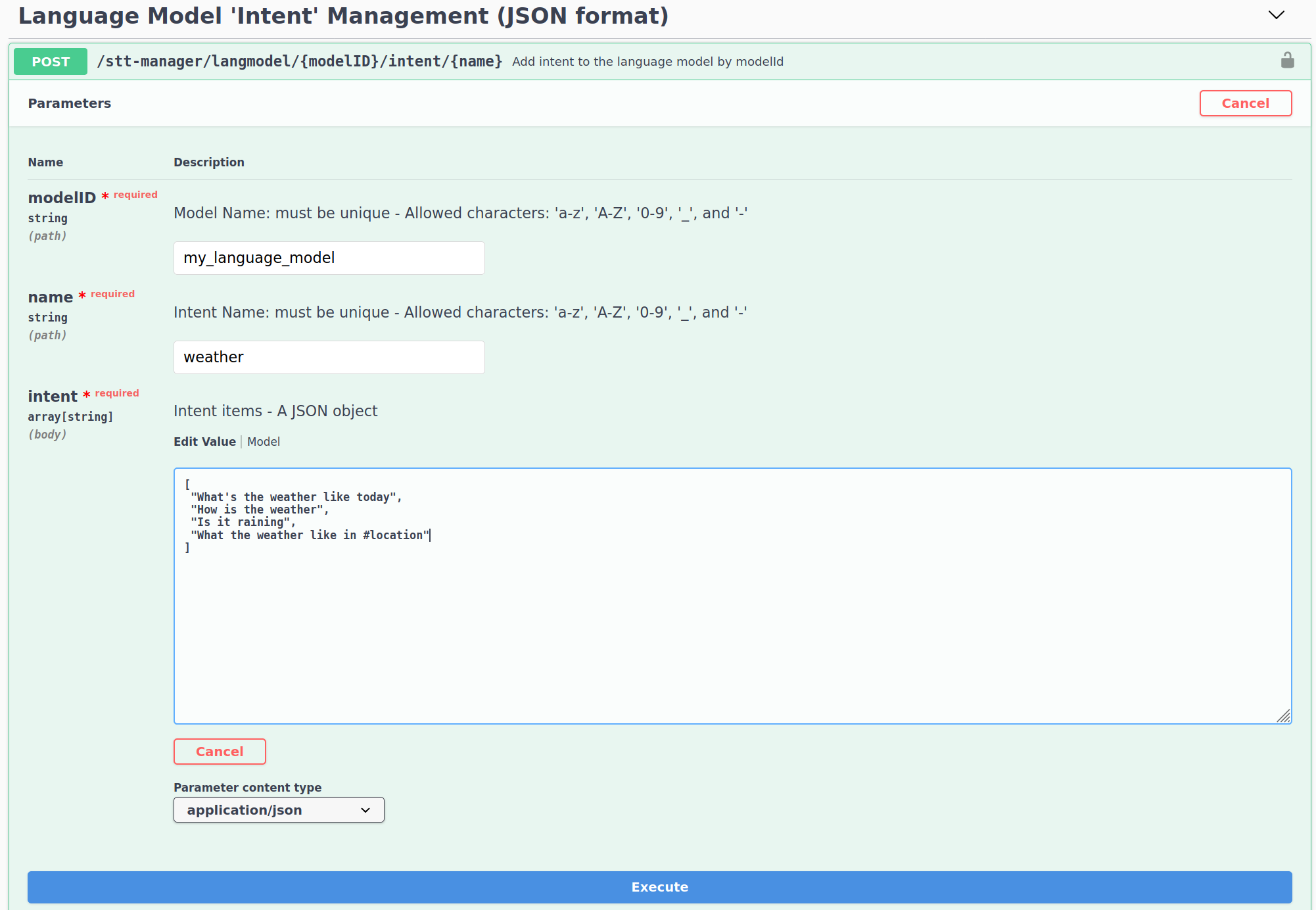
Sentences are sets using the Language Model 'Intent' Management (JSON format) section. Set the modelId of your created language model, set a name for the intention. And provide a json containing the list of utterances.
Entities are set using the Language Model 'Entity' Management (JSON format). Set the modelId of your created language model, set a name for the entities. And provide a json containing the list of value.
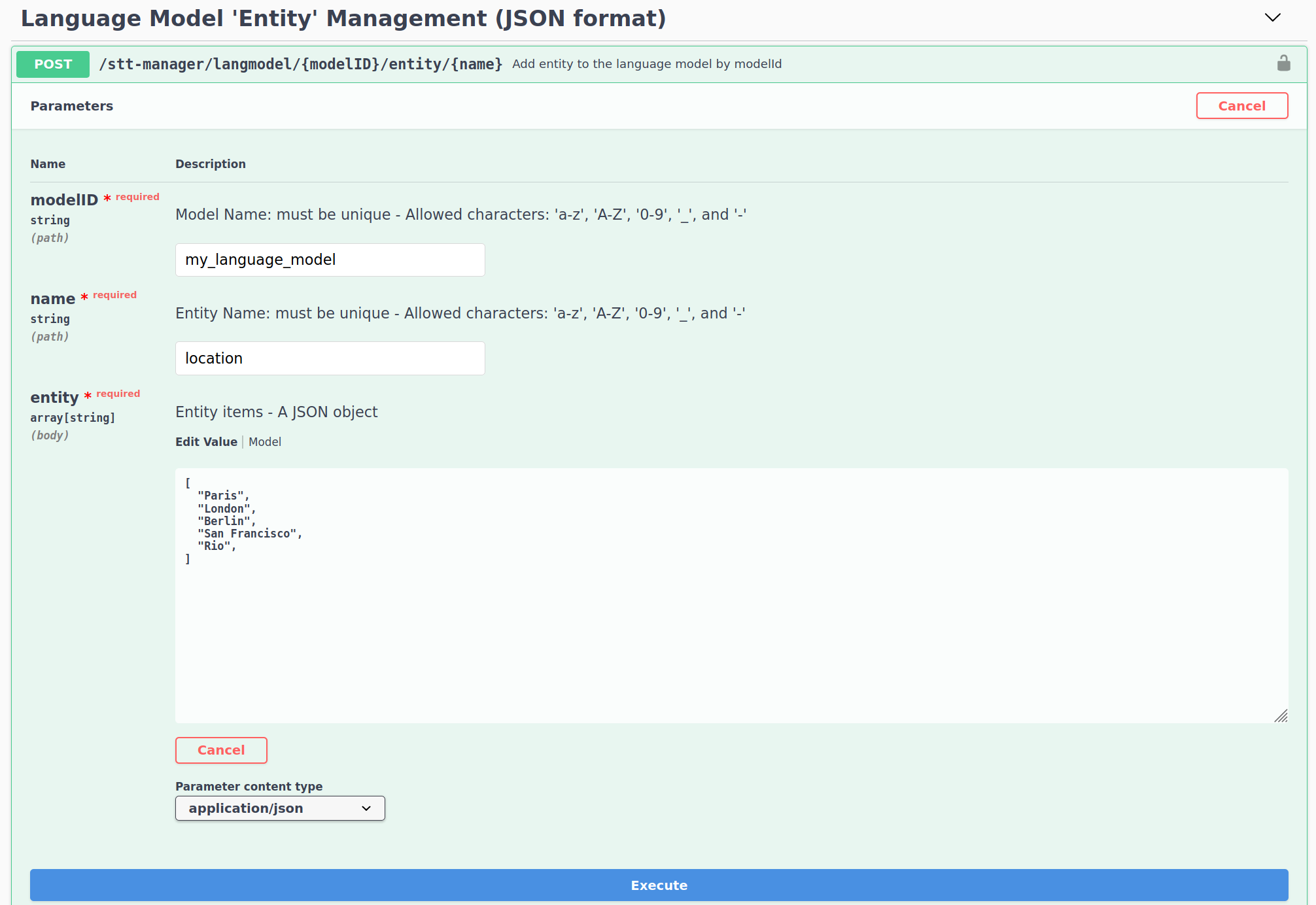
Once yours sentences and entities are input, you need to update the language model by going to the Language Model Management and call the generate/graph route. This step make take some time.
If everything has been successful, your model is now set to recognize the declared sentences/entities.
4- Submit requests
You can try submiting a request on the swagger :
serviceId: Your transcription service.file: The audio file you wish to transcribe.