Deploy a Large vocabulary file transcription service
A file transcription service allows to submit audio files to an API that will return a text transcription. File transcription can be used as itself and is a prerequisite of other uses. "Large vocabulary" implies that the transcription won't be limited to preset sentences and intend to cover an entire language.
The following step are accomplished using the LinTO Platform Service Manager web API on which requests can be executed using the swagger deployed within the platform at [LINTO_STACK_DOMAIN]/stt-manager/api-doc/.
Prerequisistes
- You have a deployed stack with LinTO Platform Service Manager running.
- You have access to the LinTO Platform Service Manager Swagger at
[LINTO_STACK_DOMAIN]/stt-manager/api-doc/. - You have created an acoustic model for your language. If not see Create an acoustic model
Creating the service
In the following steps we will create a large vocabulary file transcription service.
- Create a large vocabulary language model
- Create a file transcription service
- Submit transcription requests
1- Create a large vocabulary language model
In this step you will create a large vocabulary language model.
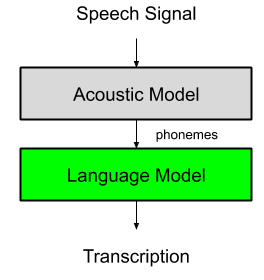
A language model takes the phonemes extracted from the audio signal by the acoustic model and map them with known sentences.
Connect to the STT Service Manager Swagger.
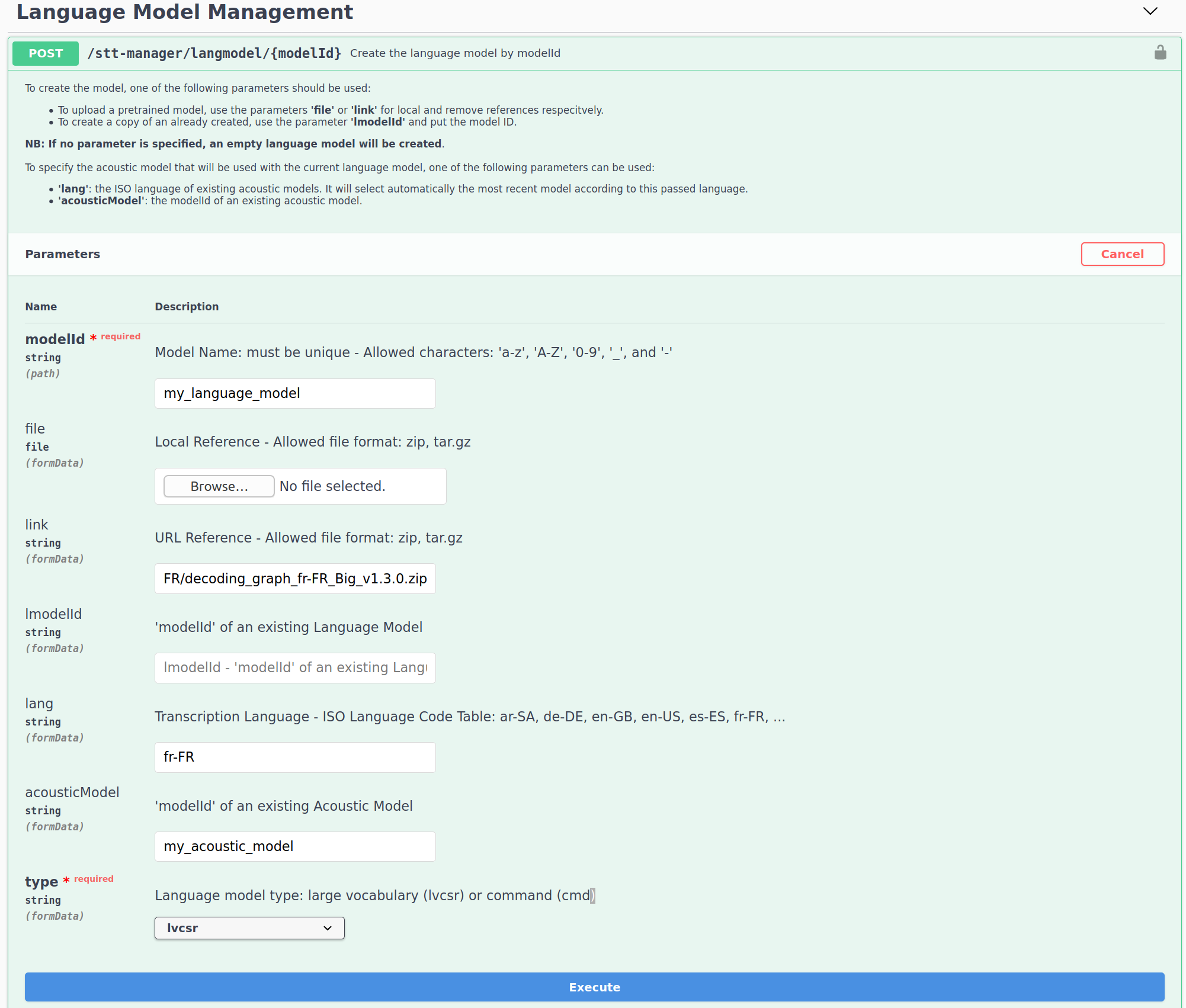
lang: The intended language.fileorlink: Set the path or the link of a large language model.acousticModel: The acoustic model you created for the intended language.type: Select lvcsr for large vocabulary.
Tap Execute and the LinTO Platform Service Manager should return a code 200.
Now you have a large vocabulary language model set in your STT Service Manager.
2- Create a file transcription service
In this step we will create a command file transcription service.
The transcription service wrap the acoustic model and the language model to produce a transcription pipeline and provide a runtime API to submit transcription requests.
Connect to the STT Service Manager Swagger.
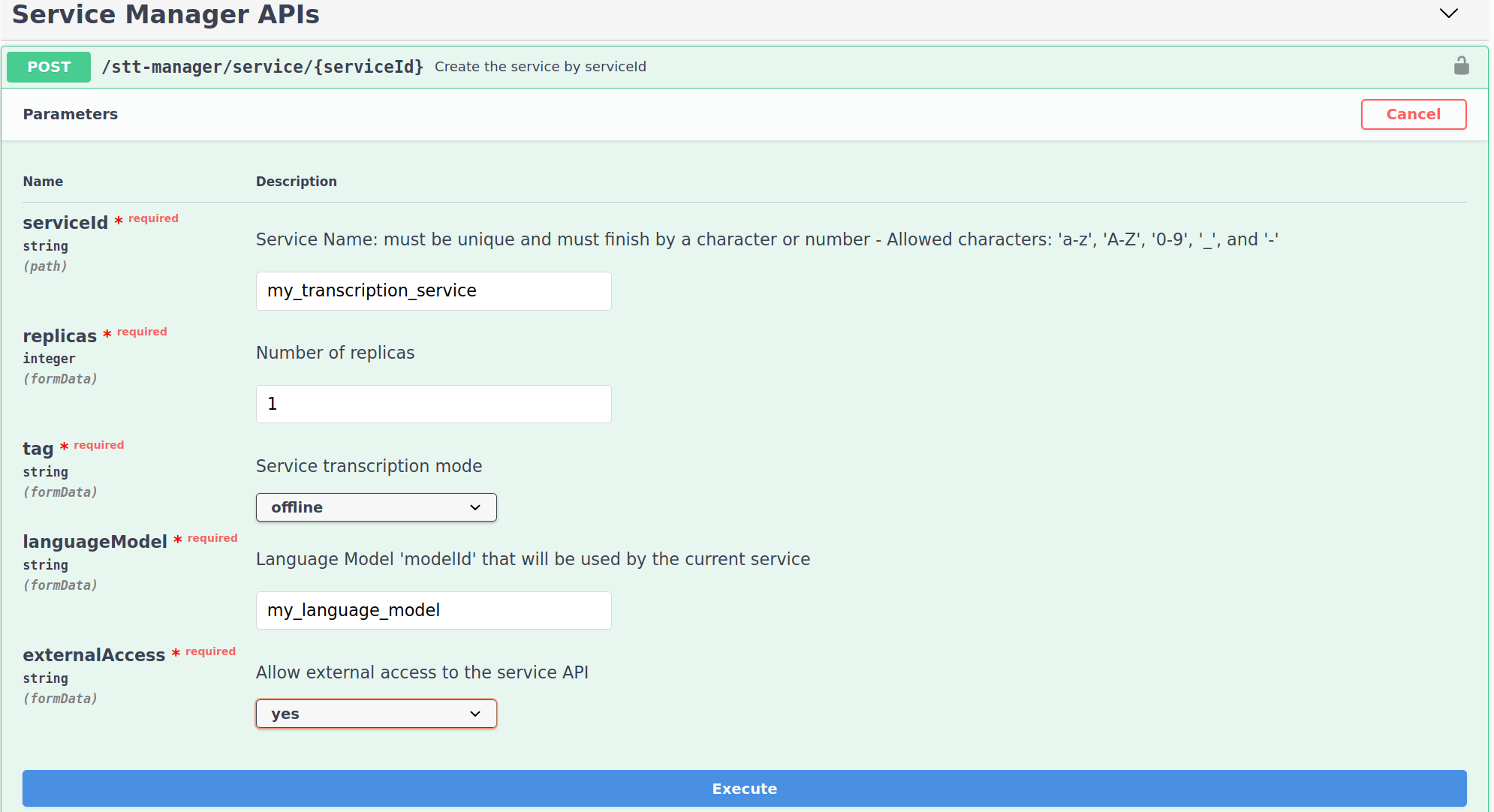
serviceId: Service Name.replica: Set the number of instance you wish to create (It can be changed later).tag: Set to offline for a file transcription service.languageModel: Set the modelId of the command language model created on the previous step.externalAccess: Whether or not the API can be accessed from outside the stack.
You have now a live large vocabulary file transcription service deployed on your stack.
3- Submit transcription requests
With the transcription service operationnal you can now execute transcription requests.
You can try submiting a request on the swagger :
serviceId: Your transcription service.file: The audio file you wish to transcribe.
Doing so will also display a template request that you may use to submit distant request.
Template request is:
curl --request POST \
--url [LINTO_STACK_DOMAIN]/stt/[serviceId]/transcribe \
--header 'accept: text/plain' \
# *optional if you plateform requires authentication --header 'authorization: Basic [authentication token]'
--header 'content-type: multipart/form-data boundary=---011000010111000001101001' \
--form file=[fileName] \
--form speaker=no \
-F "file=@[filePath]"